最近TJU需要抢课,心想着你手再快能快的过我直接发请求吗?于是想着等选课系统开放直接写一个脚本发起选课请求即可。听我舍友说,他本科也是需要抢课,但是有验证码什么的,不太好弄。
等选课系统一开,好家伙,还得先把课程搜出来才能选,而且在高峰时期还不能搜名字,得找到课程序号 / 课程代码进行准确搜索,有这功夫,请求不知道发了多少次。不过好在选课系统会提前半个小时开放,能先进去看看,还能尝试选课,但是会提示不在选课时间内,于是也是抓到了请求。
选课请求#
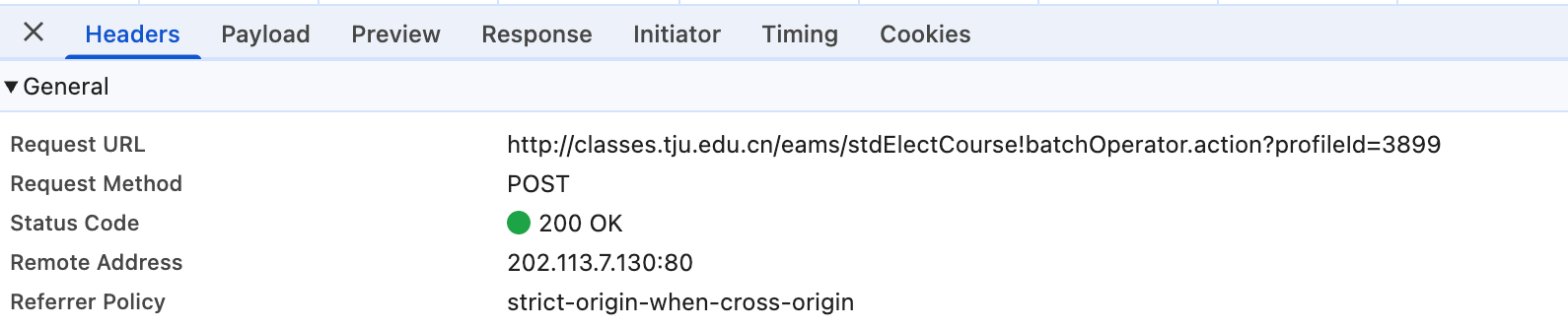
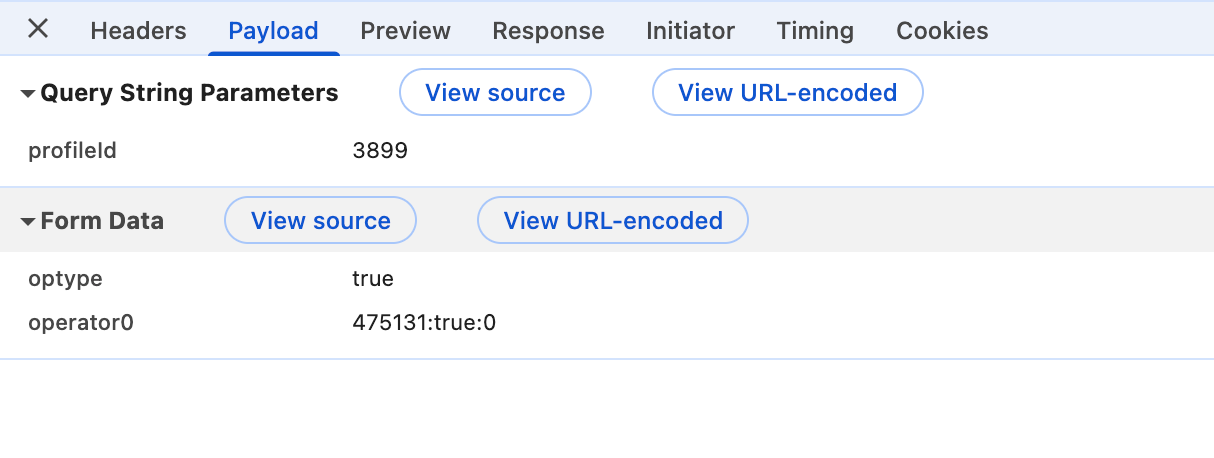
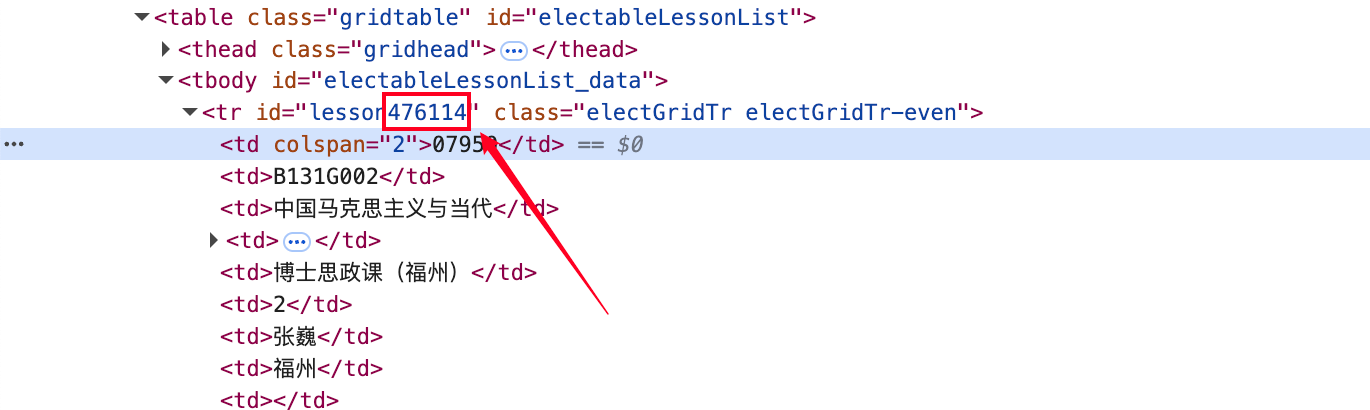
也没有什么加密数据,只有一个课程id需要替换和抓取的。但是这也没有什么难的,在html里面明晃晃的写着。
选课脚本#
需要在抢课前的几分钟进网页抓个Cookie,然后一直启动脚本就行了。需要注意设置合适的延迟,否则会一直显示点击过快。(开放的半个小时测试时间的时候就可以试一下)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
import requests
from lxml import etree
import time
url = "http://classes.tju.edu.cn/eams/stdElectCourse!batchOperator.action?profileId=3899"
cookie = ''
op_code_list = [
'476655', # 云计算
# '476672', # 高可信人工智能
# '476652', # 软件体系结构
# '474418', # 高性能计算
]
session = requests.session()
session.headers['Cookie'] = cookie
def select_course(op_code):
payload={
'optype': 'true',
'operator0': f'{op_code}:true:0'
}
headers = {
'Pragma': 'no-cache',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'
}
response = session.request("POST", url, headers=headers, data=payload, verify=False)
if '请不要过快点击' in response.text:
print(f"选课失败: 请不要过快点击")
return False
html = etree.HTML(response.text)
rep = html.xpath('//div/text()')[0].replace('\t', '').replace('\n', '')
if '失败' in rep:
print(f"选课失败: {rep}")
return False
if '成功' in response.text:
print(f"选课成功: {rep}")
return True
while True:
for op_code in op_code_list[:]:
if select_course(op_code):
op_code_list.remove(op_code)
break
else:
time.sleep(0.6)
if len(op_code_list) == 0:
break
|
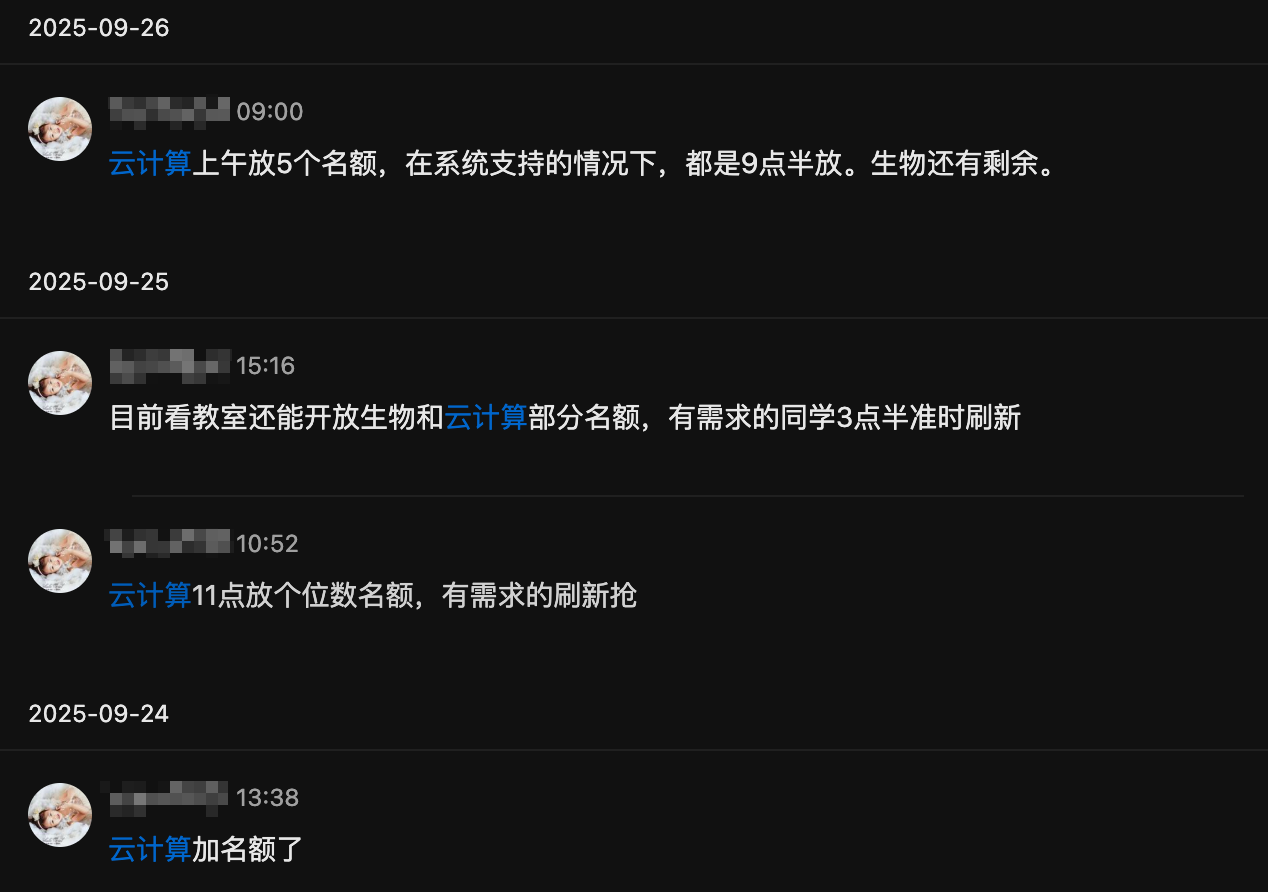
第一轮抢课忘记截图了,补一张抢个位数的课的截图。

选课心得#
研究生需要上的课不多,上学期主要需要抢的是数学和线下的热门专业课,线上课一般会有大量的名额,根本不需要抢。所以脚本里主要写这两种课的op_code就好,填上不用抢的课只会影响你抢选不上课的速度。
这里再吐槽一下TJU的放课策略,每次放名额个位数放,还没有任何前兆,你让有的人手上没电脑的怎么抢。。。而且说好三点半准时,31分多才放的。。。